Analisis Jalur (Path Analysis) dengan Menggunakan R
Bismillahirrohmanirrohim.
Assalamu'alaykum warohmatullahi wabarakatuh.
Pada kesempatan kali ini, aku tergerak untuk membuat postingan perdana dalam blog ini yang berkaitan dengan statistik karena terdapat desakan eksternal (a.k.a tugas kuliah) yang membuat penulis harus mempelajari salah satu teknik analisis multivariat yang sama sekali belum pernah aku dengar bahkan ketika aku kuliah sampai S2 hahaha. Namun, karena tuntutan perkuliahan S3 yang sedang aku jalani, sepertinya bagus jika pengalaman yang aku miliki bisa dibagikan kepada teman-teman semuanya.
Memang kenapa menggunakan R ? Sebenarnya alasannya sederhana saja karena R itu bersifat open source dan bahasa pemrograman R dikembangkan oleh orang-orang yang bertujuan untuk analisis statistik. Jadi, beberapa software "versi tani" yang teman-teman install (saya juga) seharusnya menjadi kebiasaan yang bisa dikurangi sedikit demi sedikit. Toh, ada software yang versi gratisnya, loh. Kenapa tidak mencoba mempelajarinya? Itu aja sih kayaknya. Mungkin, ada juga software lain seperti JASP maupun JAMOVI (yang ini juga baru saya dengar ketika S3) sebenarnya juga bisa sih dan gratis juga, tetapi pada tulisan kali ini akan saya gunakan R dalam menerapkan analisis jalur dalam suatu penelitian. Check it out !
A. Menetapkan direktori kerja
Pada bagian awal bekerja dengan R, kita harus menentukan lokasi folder utama yang digunakan untuk menyimpan file R, data, images, atau beberapa file lainnya yang berhubungan dengan pekerjaan kita di dalam R. Dalam kesempatan ini, saya membuat folder bernama "path analysis" pada disk D:/ saya.

B. Diagram yang menjelaskan Theory of Planned Behavior (TPB)
Langkah awal yang harus dipelajari sebelum melaksanakan analisis jalur adalah memahami teori kausal yang mendasari masalah penelitian yang sedang diselidiki. Analisis jalur akan digunakan untuk menguji teori TPB ini. Dalam penelitian ini, penulis akan menguji theory of planned behavior (TPB) yang diajukan Ajzen (1991) melalui analisis jalur. Teori ini adalah model teoretik yang menjelaskan bahwa perilaku (behavior) seseorang dipengaruhi oleh niatnya (intention) sedangkan niat seseorang ditentukan oleh sikap (attitude), norma yang berlaku (norms), dan kendali diri (control) yang dimilikinya. Namun, menurut TPB, tidak ada pengaruh antara attitude, norms, dan control terhadap behavior secara langsung. Dengan kata lain, hanya terdapat pengaruh langsung attitude, norms, control terhadap intention dan intention terhadap behavior. Kemudian, terdapat pengaruh tidak langsung attitude, norms, control terhadap behavior melalui variabel mediasi yaitu intention. Penelitian ini akan membuktikan kebenaran teori TPB dengan menggunakan analisis jalur. Gambar di bawah merepresentasikan diagram jalur dari Theory of Planned Behavior.

C. Input dataset
Pada bagian ini, kita menentukan letak dimana file data berada. Dalam hal ini, file data disimpan dalam format “PATHAMOS100.csv” yang terletak di dalam “D:/path analysis/data/PATHAMOS100.csv”. Tetapi, karena kita telah menentukan letak direktori kerja pada “D:/path analysis” maka kita cukup mengetik “data/PATHAMOS100.csv” saja. Folder "data" terletak pada direktori folder "path analysis" yang sudah kita buat di awal tadi. Jika teman-teman ingin mengunduh data yang digunakan dalam analisis kali ini klik link ini ya.

1. Preview data
Bagian di bawah ini merupakan pratinjau 6 data pertama yang digunakan dalam analisis kita dimana terdapat 5 variabel yang terdiri dari 3 variabel eksogen (attitude, norms, control) dan 2 variabel endogen (intention & behavior).

2. Statistik deskriptif
Pada bagian ini, ditampilkan statistik deskriptif setiap variabel di dalam dataset. Dapat dilihat bahwa terdapat 100 baris data (dilihat pada kolom n). Kelima variabel memiliki skor dengan skala antara 1 sampai 6 yang dapat dilihat dari kolom min dan max. Terdapat beberapa variabel memiliki standar deviasi yang hampir mirip seperti attitude (0.77) dan behavior (0.73) serta norms (1.06) dan control (1.01).

Untuk memeriksa normalitas data, kita bisa tinjau dari plot histogram dan boxplot-nya. Berdasarkan plot distribusi histogram, terdapat 3 variabel yang mendekati distribusi normal (norms, intention, behavior). Sedangkan untuk attitude dan control memiliki skewness negatif. Distribusi yang diharapkan digambarkan dengan plot garis titik-titik (......) sedangkan plot garis strip (-----) adalah realita data yang ada.

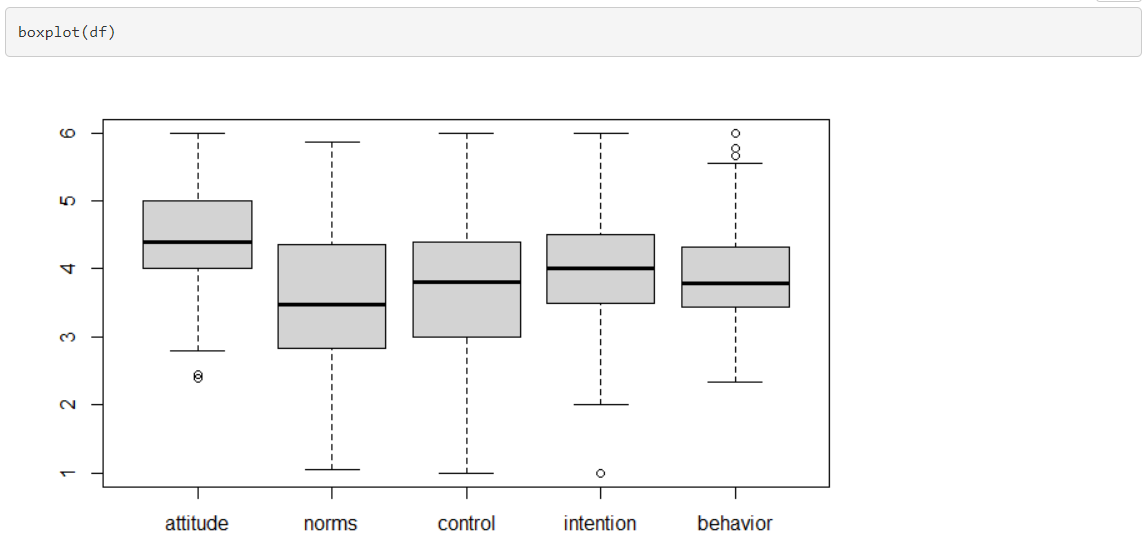
Selain histogram, kita juga bisa menggunakan boxplot untuk mengambarkan distribusi data. Batas garis putus-putus menunjukkan range dari setiap data variabel yaitu (min 1 dan max 6). Kemudian, “box” yang dibuat menggambarkan letak Q3, Q2 (median, garis tebal di tengah), dan Q1. Outlier (pencilan) biasanya akan terdeteksi jika terdapat titik-titik data diluar “box” ini. Berdasarkan boxplot yang ditampilkan, terdapat pencilan pada data attitude, intention, dan behavior.
D. Asumsi analisis
Sama seperti asumsi regresi linear yaitu asumsi yang umum digunakan adalah residu yang berdistribusi normal dan ada beberapa asumsi tambahan yang harus dipenuhi dalam analisis jalur antara lain :
- Variabel data harus memiliki skala pengukuran yang kontinyu (interval atau rasio).
- Variabel data dalam model bebas kesalahan pengukuran (reliabel).
- Model hubungan bersifat rekursif (satu arah dan tidak berkebalikan).
- Residu tidak berhubungan satu sama lain.
- Hubungan arahnya adalah linear dan additif.
E. Analisis jalur dengan pendekatan regresi linier berganda
Pada dasarnya, terdapat dua pendekatan yang bisa digunakan untuk melakukan analisis jalur yaitu regresi linear berganda dan model fitting. Keduanya akan mengeluarkan hasil yang sama. Untuk percobaan pertama, kita akan lakukan dengan pendekatan regresi linear berganda.
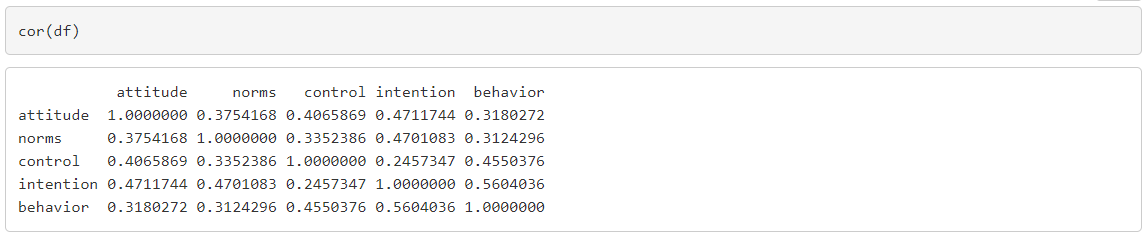
1. Menentukan korelasi antar variabel eksogen
- Antara attitude ~~ norms memiliki korelasi 0.375
- Antara attitude ~~ control memiliki korelasi 0.406
- Antara norms ~~ control memiliki korelasi 0.335
2. Spesifikasi model A (intention model)
Pada model A (intention model), kita ingin memodelkan pengaruh langsung attitude, norms, dan control terhadap intention melalui pendekatan regresi linear berganda.


3. Estimasi model A (intention model)

4. Hasil pemodelan A (intention model)

5. Menampilkan koefisien jalur (Beta) untuk model A

6. Spesifikasi model B (behavior model)
Pada model B (behavior model), kita ingin memodelkan pengaruh langsung intention terhadap behavior melalui pendekatan regresi linear.


7. Estimasi model B (behavior model)

8. Hasil pemodelan B (behavior model)

9. Menampilkan koefisien jalur (Beta) untuk model B

10. Menentukan error pada model A (intention model) dan model B (behavior model)

11. Gambar analisis jalur dengan pendekatan regresi linear berganda
Berdasarkan nilai kovarians/ korelasi (attitude~norms, attitude~control, norms~control), beta (attitude, norms, control, intention), dan error (model A dan model B) yang telah kita peroleh sebelumnya, selanjutnya bisa digambarkan dalam diagram jalur seperti di bawah ini.

F. Import library analisis jalur dengan pendekatan model fitting
Latent Variable Analysis atau “lavaan” adalah library open source yang dikembangkan dalam pemrograman R untuk mengerjakan berbagai macam analisis multivariat termasuk analisis jalur, CFA, SEM, dan growth curve model (dokumentasi lebih lengkapnya dapat dilihat di lavaan.ugent.be).

G. Analisis jalur dengan pendekatan model fitting
1. Spesifikasi model
Berbeda dengan pendekatan regresi linear berganda dimana analisis kovarians, intention model, dan behavior model dilaksanakan secara terpisah. Dengan pendekatan model fitting, kita bisa menspesifikasi model-model ini secara langsung dalam satu kali spesifikasi (simultan).

2. Estimasi pemodelan

3. Hasil pemodelan dengan model fitting



H. Bagaimana menentukan derajat kebebasan ?
Terdapat lima variabel unik yaitu intention, attitude, norms, control, behavior.
Untuk mengetahui berapa komponen kovarians dan varians unik dalam matriks kovarians (korelasi), kelima variabel ini adalah lower diagonal dari matriks kovarians/ korelasi.
Formula untuk menentukan jumlah informasi unik non redundant = V(V + 1)/2 (Meyers, Gamst, & Guarino, 2016).
dimana V = jumlah variabel di dalam data = 5
Maka, jumlah informasi unik non redundant dalam model = 15
Jumlah parameter = banyaknya parameter estimate dalam model yaitu jalur langsung (4), error terms(2), varians (3) dan kovarians variabel eksogen (3) = 12 (lihat tabel di atas “number of model parameters”)
Derajat kebebasan = 15 - 12 = 3
Lihat “Degrees of freedom” pada model test user output diatas. Apakah hasilnya sesuai ?
Nilai ini lebih besar daripada nol (0) yang berarti bahwa model overidentified artinya kita bisa menginterpretasikan model fit dengan beberapa indeks fitting di bawah ini.
I. Lima indeks fit yang perlu diperhatikan untuk evaluasi model
1. Chi square test
Dalam hasil kita, Model Fit Test Statistics menunjukkan statistik Chi square (17.574) dan p-value sama dengan 0.001 lebih kecil dari 0.05 yang berarti bahwa Ho ditolak atau Model tidak fit terhadap data.
2. Comparative Fit Index (CFI)
Dalam hasil kita ditemukan CFI = 0.881 dimana kriterianya CFI > 0.9 yang berarti bahwa model tidak fit terhadap data.
3. Tucker Luwis Index (TLI)
Dalam hasil kita ditemukan TLI = 0.602 dimana kriterianya TLI > 0.95 yang berarti bahwa model tidak fit terhadap data.
4. Root Mean Square Error of Approximation (RMSEA)
Dalam hasil kita ditemukan RMSEA = 0.220 dimana kriterianya RMSEA < 0.08 yang berarti bahwa model tidak fit terhadap data.
5. Standardized Root Mean Square Residual (SRMR)
Dalam hasil kita ditemukan bahwa SRMR adalah 0.084 dimana kriterianya SRMR < 0.08 yang berarti bahwa model tidak fit dengan data.
Berdasarkan kelima indikator evaluasi ini menyimpulkan bahwa model analisis jalur kita belum fit terhadap data yang tersedia. Kemungkinan terdapat jalur yang tidak signifikan yang disebabkan oleh variabel norms. Dengan demikian, kita harus kembali ke tahap spesifikasi parameter model dan memotong jalur yang tidak signifikan ini.
J. Persamaan regresi dan R-Squared
- Lihat p-value pada output Regression jika < 0.05 berarti berpengaruh secara signifikan.
- Nilai koefisien jalur (beta) lihat pada Std.all masing-masing variabel prediktor.
- Kemudian errornya lihat pada Variances pada Std.all. Agar nilainya sama dengan error pada pendekatan regresi linear carilah akar daripadanya.
- R-squared menjelaskan seberapa besar varians variabel bebas menentukan varians variabel terikat.
Demikianlah apa yang bisa saya sampaikan pada postingan kali ini terkait denan menerapkan analisis jalur pada theory of planned behavior (TPB) dengan menggunakan R. Semoga bermanfaat kepada teman-teman pembaca semuanya. Mohon perbaikannya jika terdapat kesalahan konseptual dan prosedural dalam analisis ini. Matur nuwun.
Wabilahi taufik wal hidayah.
Wassalamu’alaykum warahmatullohi wabarokatuh.
Ditulis oleh : Purwoko Haryadi Santoso



Komentar
Posting Komentar
Silakan berdiskusi pada kolom komentar yang telah disediakan. Terima kasih.